کش L1 و L2 چیست و چگونه کار میکند؟
موبنا- از سه دهه پیش دانشمندان و مهندسان کامپیوتر به فکر استفاده از حافظههای پرسرعت کش در کنار پردازندهها افتادند. این حافظهها با سرعت بسیار بالای خود، اطلاعات را در زمانی بسیار کم به پردازنده رسانده و در تسریع عمل پردازش نقش به سزایی دارند. توسعه حافظههای کش و پردازش کش، یکی از مهمترین رویدادهای تاریخ …

موبنا- از سه دهه پیش دانشمندان و مهندسان کامپیوتر به فکر استفاده از حافظههای پرسرعت کش در کنار پردازندهها افتادند. این حافظهها با سرعت بسیار بالای خود، اطلاعات را در زمانی بسیار کم به پردازنده رسانده و در تسریع عمل پردازش نقش به سزایی دارند. توسعه حافظههای کش و پردازش کش، یکی از مهمترین رویدادهای تاریخ صنعت پردازش اطلاعات است. اگر بخواهیم موارد استفاده از کش را برشماریم، به فهرستی بیانتها از پردازندههای ریز و درشت خواهیم رسید، چرا که از کوچکترین و کم مصرفترین پردازندههای Cortex A5 کمپانی آرم تا قدرتمندترین پردازنده Core i7 اینتل، تماما از حافظه کش در ساختار خود بهره میبرند. حتی میکروکنترلرهای رده بالا نیز همگی یا از کش بهره میبرند و یا سازندگانشان حداقل آن را به عنوان یک انتخاب اضافه در کنار این محصولات به مشتریان خود پیشنهاد میدهند. کش به این دلیل اهمیت دارد که سرعت پردازش اطلاعات را به نحو چشمگیری افزایش میدهد و افزایش سرعت نیز امری غیر قابل چشم پوشی است، حتی اگر پردازنده سیستم بسیار کوچک و در حد یک میکروکنترلر باشد.
کش برای رفع یک مشکل مهم اختراع و به کار گرفته شد. در اوایل راه صنعت پردازش داده، حافظهها بسیار کند و فوقالعاده گران بودند. در کنار این حافظهها نیز پردازندههایی قرار داشتند که از سرعت بالایی برخوردار نبودند. از اوایل دههی ۱۹۸۰، این اختلاف سرعت بین حافظه و پردازنده شروع به افزایش کرد. سرعت کلاک ریز پردازندهها افزایش پیدا کرد، اما سرعت دسترسی به دادههای ذخیره شده در حافظه با کندی بسیار در حال ارتقا بود. با افزایش این شکاف سرعت، دانشمندان به این نتیجه رسیدند که باید از نوعی حافظه جدید و سریعتر در سیستمها استفاده کرد. شکل زیر به شما در درک مطالب گفته شده کمک میکند.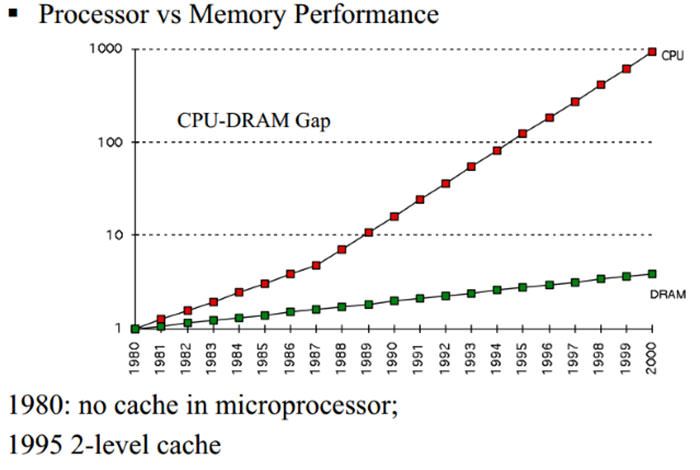
کش چگونه کار میکند؟
کش پردازنده، در واقع مخزنی از نوع حافظه پر سرعت است و اطلاعاتی که پردازنده بیشتر به آنها نیاز دارد را در خود ذخیره میکند تا همواره آنها را نزدیک پردازنده داشته باشیم. این که دقیقا چه اطلاعاتی در درون کش قرار میگیرند، بستگی به الگوریتمهای پیچیده و فرضیات خاصی درباره برنامه در حال اجرا دارد. هدف استفاده از سیستم کش، این است که مطمئن شویم هنگامی که پردازنده برای یافتن بیت بعدی از اطلاعات مورد نیازش به جستجو میپردازد، بلافاصله آن را به صورت آماده در حافظه کش بیابد. به این وضعیت، Cache Hit میگویند. در مقابل، وضعیت دیگری نیز وجود دارد که با نام Cache Miss شناخته میشود. این وضعیت هنگامی رخ میدهد که پردازنده، اطلاعات مورد نظر خود را در حافظه کش نیافته و ناچار به جستجو در حافظههای دیگر شود. اینجاست که حافظه کش سطح ۲ (L2 Cache) مورد استفاده قرار میگیرد. این نوع کش گرچه نسبت به حافظه کش سطح ۱ (L1 Cache) کندتر است، اما گنجایش بسیار بیشتری دارد. برخی از پردازندهها از طراحی کش تو در تو (Inclusive) استفاده میکنند. در این نوع طراحی، اطلاعات ذخیره شده در کش L1، در L2 نیز کپی میشوند. بدین ترتیب کش L2 حاوی اطلاعات کش L1 و مقدار اضافهای از اطلاعات دیگر است. سایر پردازندهها از طراحی کش انحصاری (Exclusive) استفاده میکنند. در این نوع طراحی، اطلاعات درون حافظههای کش L1 و L2 کاملا منحصر به فرد بوده و این دو هیچ گونه اطلاعات مشترکی ندارند. اگر پردازنده موفق به یافتن اطلاعات در حافظههای کش L1 و L2 نشود، به جستجو در لایه سوم کش (L3 Cache) میپردازد. اگر اطلاعات آنجا هم نبودند، در صورت وجود کش L4، به آن مراجعه میکند و اگر اطلاعات باز هم پیدا نشدند، به جستجو در حافظه رم پویا (DRAM) میپردازد.
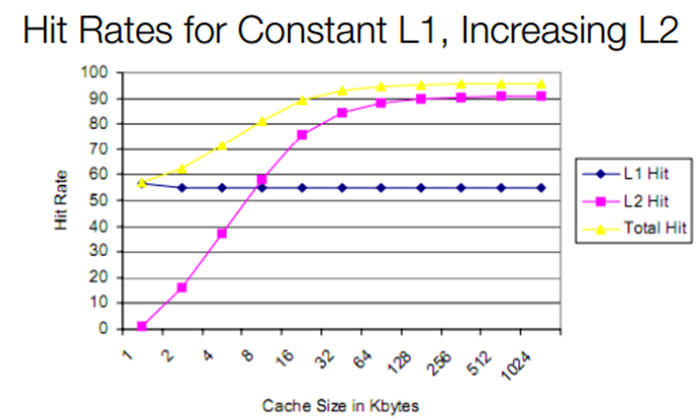


نمودار بالا، رابطه بین یک کش L1 با Hit Rate ثابت را با یک کش L2 نشان میدهد. Hit Rate یکی از مشخصههای مربوط به حافظههای کش و بیانگر میزان دسترسی پردازنده به اطلاعات مورد نیاز خود در حافظه کش است. این مشخصه به صورت درصدی بیان میشود. مثلا اگر Hit Rate حافظه کش L1 برابر با ۹۰ درصد باشد، نتیجه میگیریم که پردازنده در هر بار مراجعه به کش L1، حدودا ۹۰ درصد اطلاعات مورد نیاز خود را در آن یافته و برای یافتن ۱۰ درصد باقی مانده باید به کش L4، L3، L2 یا حتی حافظه رم مراجعه کند. با کمی دقت متوجه میشویم که هرچه گنجایش کش L2 بیشتر میشود، Hit Rate کل هم بالا میرود. دلیلی آن هم کمتر شدن احتمال رجوع پردازنده به حافظههای کش کند L3 و L4 و افزایش سرعت کلی سیستم است. یک کش L2 بزرگتر، ارزانتر و کندتر، میتواند تمام مزایای یک کش L1 را بدون هدر دادن فضای تراشه و برد و انرژی الکتریکی برای ما تامین کند. اغلب حافظههای کش L1 جدید، Hit Rate های بسیار بالاتر از ۵۰ درصد نشان داده شده در اینجا را دارند اینتل و AMD حتی توانستهاند Hit Rate کشهای خود را به بالای ۹۵ درصد برسانند.
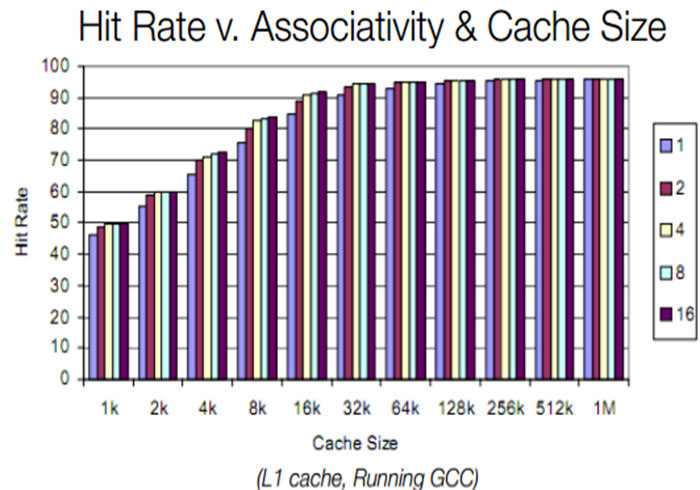
مبحث مهم بعدی، شرکتپذیری مجموعهای (set-associativity) است. هر یک از انواع پردازنده در درون خود دارای نوعی حافظه رم است که رم برچسب (Tag RAM) نامیده میشود. رم برچسب، سابقهای از تمام مکانهای حافظه است که میتواند متناظر با هر بلوک کش باشد. اگر یک کش کاملا شرکت پذیر باشد، بدان معناست که هر بلوک حافظه رم میتواند در یک بلوک حافظه کش دلخواه ذخیره شود. مزیت چنین سیستمی Hit Rate فوقالعاده بالای آن است، چرا که تمام اطلاعات موجود در رم، در کمترین زمان ممکن از طریق حافظه کش در اختیار پردازنده قرار داده میشوند، اما زمان فرایند جستجو بسیار طولانی میشود، چرا که پردازنده قبل از جستجو در حافظه اصلی باید ابتدا تمام حافظه کش را جستجو کند.
در سوی دیگر، حافظهی Direct-Mapped Cache وجود دارند. در این نوع حافظهها، هر بلوک حافظه کش میتواند شامل فقط و فقط یک بلوک از حافظه رم باشد. این نوع کش دارای سرعت جستجوی بسیار بالایی است، اما از آنجا که از نگارش یک به یک بلوکهای رم بر روی خود بهره میبرد، طبیعتا Hit Rate پایینی دارد. به جز این دو روش، روش دیگری نیز برای کارکرد کش وجود دارد که شرکت پذیری چند حالته (n–way associativity ) نام دارد. این متد تلاش میکند هر دو فاکتور سرعت جستجو و Hit Rate کش را در حد معقول و مناسبی نگه دارد. اما چگونه؟ در n-way associativity، هر بلوک از حافظه رم میتواند بر یکی از n بلوک تعیین شده در حافظه کش نگاشته شود. مثلا در شرکت پذیری چهار حالته، هر بلوک حافظه رم میتواند بر یکی از ۴ بلوک تعیین شده در حافظه کش نگاشته شود. این روش نسبت به نگارش کاملا شرکت پذیر، سرعت جستجوی بالاتر و نسبت به نگارش مستقیم، Hit Rate بالاتری دارد. با نگاهی به نمودار زیر میتوان تاثیر شرکت پذیری مجموعهای را بر افزایش Hit Rate حافظه کش دید. به یاد داشته باشد که Hit Rate دو حافظه کش فقط و فقط زمانی قابل مقایسه است که هر دو در کنار پردازنده و حافظه رمی یکسان، به اجرای یک اپلیکیشن واحد بپردازند، چرا که Hit Rate برای هر اپلیکیشن متفاوت است.
چرا کش پردازندهها در حال بزرگتر شدن است؟
شرکتهای سازنده، روز به روز میزان حافظه کش پردازندههای خود را افزایش میدهند، زیرا هرچه حافظه کش بزرگتر باشد، دسترسی پردازنده به اطلاعات ضروری بیشتر شده و میزان مراجعه آن به حافظه رم برای دریافت اطلاعات کمتر میشود. همین امر در اغلب موارد موجب صرفه جویی در وقت و افزایش سرعت کارکرد سیستمها میشود.
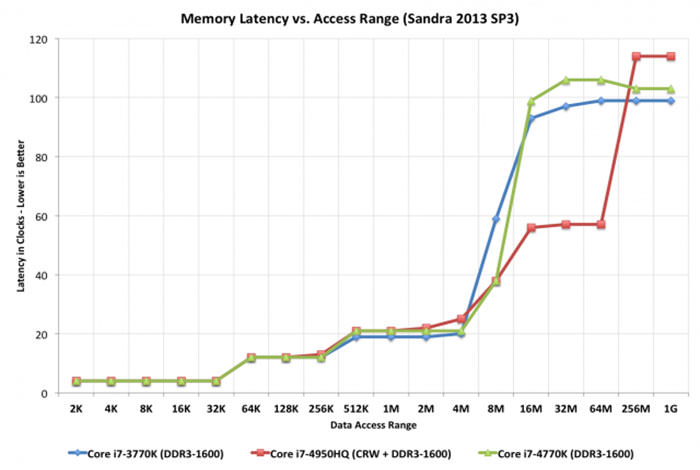
نمودار بالا مربوط به بررسی وبسایت انندتک از یکی از پردازندههای سری Haswell اینتل است. محور عمودی تاخیر دسترسی را نشان میدهد که هرچه کمتر باشد بهتر است. محور افقی نیز نشان دهنده حجم فایلهای مورد نظر برای آزمایش سیستم است. در شکل میبینیم که افزودن یک حافظه غول پیکر ۱۲۸ مگابایتی به عنوان کش L4 به پردازنده، چه تاثیر مثبتی بر روی عملکرد سیستم دارد. هر پله نشان دهنده افزوده شدن یک لایه کش به سیستم است. خط شکسته قرمزرنگ، نشان دهنده سیستمی است که از کش L4 بهره میبرد. برای فایلهای بزرگ، عملکرد این سیستم تقریبا دو برابر بهتر از دو سیستم دیگر است.
ممکن است استفاده از کشهای بسیار بزرگ برای افزایش سرعت سیستم منطقی به نظر برسد، اما به گفته متخصصان، این کار به صرفه نیست. کشهای بزرگتر هم گران هستند و هم کند. از سویی دیگر، بهتر است به جای صرف کردن بودجه بیش از حد برای بزرگتر کردن کش، به بهبود عملکرد واحدهای دیگر سیستم بپردازیم. این هزینه را میتوان برای افزایش تعداد یا بهبود عملکرد هستههای سیستم به کار برد. تصویر زیر، یک پردازنده پنتیوم (Pentium) اینتل را نشان میدهد. حافظه کش L2 غول پیکر این پردازنده، تمام نیمه سمت چپ پردازنده را در بر گرفته است!

تاثیر نحوه طراحی حافظه کش بر عملکرد سیستم چگونه است؟
تاثیر افزودن یک حافظه کش به پردازنده بر عملکرد سیستم، بستگی به میزان Hit Rate آن دارد. بالا رفتن Cache Miss نیز تاثیر فاجعه باری بر عملکرد کلی پردازنده و سیستم خواهد داشت. مثال زیر بسیار ساده اما کاربردی است.
فرض کنید که یک پردازنده باید صد داده را از یک کش L1 بخواند. این کش، تاخیر دسترسی یک نانو ثانیه و Hit Rate صد درصدی دارد. پس قاعدتا ۱۰۰ نانو ثانیه زمان لازم است تا پردازنده ما بتواند تمام اطلاعات مورد نیازش را از کش بخواند. حال فرض کنید که کش دارای Hit Rate برابر با ۹۹ درصد است. پس قاعدتا ۹۹ داده اول مورد نیاز پردازنده در کش L1، و صدمین داده در کش L2 با تاخیر دسترسی ۱۰ نانو ثانیه قرار گرفتهاند. این بدان معناست که پردازنده به ۹۹ نانو ثانیه زمان برای خواندن ۹۹ داده اول موجود در کش L1 و ۱۰ نانوثانیه برای خواندن صدمین داده از کش L2 نیاز دارد. البته یک نانوثانیه نیز صرف جستجو به دنبال داده صدم در کش L1 میشود که پس از عدم موفقیت، پردازنده به جستجو در کش L2 میپردازد. بنابراین پردازش مورد نظر این بار در ۱۱۰ نانوثانیه انجام میشود. همان طور که ملاحظه میکنید، تنها یک درصد افت Hit Rate در این مثال، موجب کاهش ۱۰ درصدی سرعت پردازنده در خواندن دادهها شد.
در دنیای واقعی، Hit Rate یک کش L1، بین ۹۵ تا ۹۷ درصد است، اما اگر از دو کش L1 با Hit Rate های ۹۵ و ۹۷ درصد در دو سیستم یکسان استفاده کنیم، اختلاف سرعت به وجود آمده برای ما ۲ درصد نخواهد بود، بلکه طبق محاسبات، این اختلاف به بیش از ۱۴ درصد میرسد! در نظر داشته باشید که ما فرض را بر آن گذاشتیم که دادههای یافت نشده در کش L1، تماما در کش L2 موجود باشند. اگر دادههای مورد نظر در هیچکدام از حافظههای کش قرار نگرفته باشند، پردازنده باید در حافظه رم که دارای تاخیر دسترسی بین ۸۰ تا ۱۲۰ نانو ثانیه است به دنبال دادهها بگردد. در این حالت، سرعت سیستمی که Hit Rate کش L1 آن ۹۷ درصد است، حدودا ۵۰ درصد بیشتر از سیستمی با Hit Rate حدود ۹۵ درصد است!
وقتی خانواده پردازندههای بولدوزر AMD با خانواده Core i اینتل مقایسه میشوند، اهمیت طراحی کش و تاثیر آن بر عملکرد سیستم معلوم میشود. اینتل در این مقوله فوق العاده عمل کرده، اما AMD این گونه نبوده است. هنوز معلوم نیست چه مقدار از تقصیرات عملکرد نه چندان جالب پردازنده AMD را میتوان به گردن کش نهچندان سریع آن انداخت. پردازندههای خانواده بولدوزر AMD، علاوه بر داشتن تاخیرهای نسبتا بالا، از تداخل و درگیری کش رنج میبرند. AMD، دستورالعمل کش L1 هر بولدوزر خود را در جدولی مانند جدول زیر منتشر کرده است:
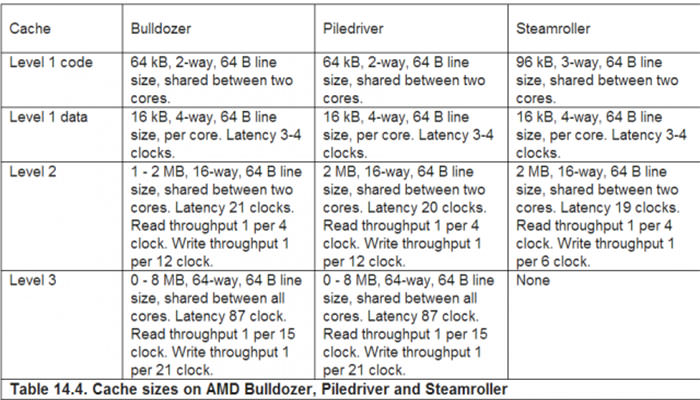
یک کش هنگامی دچار درگیری و تداخل میشود که دو رشته به صورت همزمان بخواهند اطلاعات خود را در یک قسمت از حافظه نوشته و بازنویسی کنند. این عمل موجب افت شدید عملکرد هر دو رشته میشود. در این حالت، هر هسته پردازنده مجبور میشود فقط دادههای ارجح خود را در کش بنویسد تا هسته دیگر فورا اطلاعات را بازنویسی کند! پردازنده AMD به خاطر این مشکل به شدت افت کرد. حتی تلاش AMD برای رساندن کش کد L1 به ۹۶ کیلوبایت و طراحی کش بر اساس روش شرکت پذیری سه حالته هم کارساز نبوده و این پردازنده نتوانست توفیقی کسب کند.
شکل بالا نشان میدهد که چگونه زمانی که هر دو هسته پردازنده Opteron 6276 (یکی از پردازندههای خانواده بولدوزر AMD) با هم فعال بودند، Hit Rate آن پایین آمده است. کاملا واضح است که درگیری کش تنها مشکل این پردازنده نبود، چرا که حتی هنگام برابری Hit Rate ها نیز Opteron 6276 به سختی توان رقابت با مدل Opteron 6174 را داشت!

دانشمندان و محققان کامپیوتر در تلاش هستند تا عملکرد بهتری را از کشهای کوچکتر دریافت کنند و همین امر موجب شده است که ساختار و طراحی این قطعات روز به روز پیشرفت کند. تراشههای سری Haswell و Broadwell اینتل که از کش L4 با حجم زیاد بهره میبرند، گواهی بر درستی این قانون هستند.
معلوم نیست که آیا AMD این مسیر را تا سقوط بخش پردازنده خود ادامه میدهد یا استراتژی دیگری برای جلب اعتماد کاربران به کار خواهد گرفت. تاکید بسیار این کمپانی بر HSA یا همان معماری سیستم ناهمگون (Heterogeneous System Architecture) و استفاده از منابع مشترک برای عملیاتی کردن آن باعث شده است تا این کمپانی در مسیر متفاوتی قرار گیرد. فقط میتوان گفت که در حال حاضر، چیپهای پردازشگر AMD تواناییهای لازم برای توجیه هزینه پرداختی خود را ندارند!
طراحی بهینه حافظههای کش، مصرف کمتر انرژی و بازدهی بیشتر، نه تنها برای پردازندههای چند سال آینده بسیار حیاتی خواهند بود، بلکه در زمان کنونی هم اگر یک کمپانی بتواند تغییری اساسی در هر کدام از آنها به وجود بیاورد، به شکلی حیرت انگیز وضعیت مالی خود را بهبود میبخشد!
منبع:زومیت|نویسنده:محمد طولابی
